

")
This paper address the critical task of legal case retrieval, which is essential in intelligent legal systems.
While pre-training has succeeded in ad-hoc retrieval, effective strategies for legal case retrieval are still questioned. Legal case documents have intricate logical structures, but existing language models struggle with long-distance dependencies and key legal elements. To tackle these issues, this paper proposes SAILER, a Structure-Aware pre-trained Language Model for Legal Case Retrieval. SAILER optimizes retrieval by utilizing structural information, attending to key legal elements, and employing an asymmetric encoder-decoder architecture for pre-training. This model demonstrates strong discrimination capabilities without legal annotation data, distinguishing cases accurately. Experiments show significant improvements over state-of-the-art methods in legal case retrieval.
Challenges Addressed
- Long Document Structures: Legal case documents are lengthy with inherent logical structures, posing challenges for existing models in capturing long-distance dependencies.
- Relevance in Legal Domain: Relevance in legal case retrieval hinges on key legal elements, differentiating cases significantly. Existing models struggle with understanding these elements.
Approach
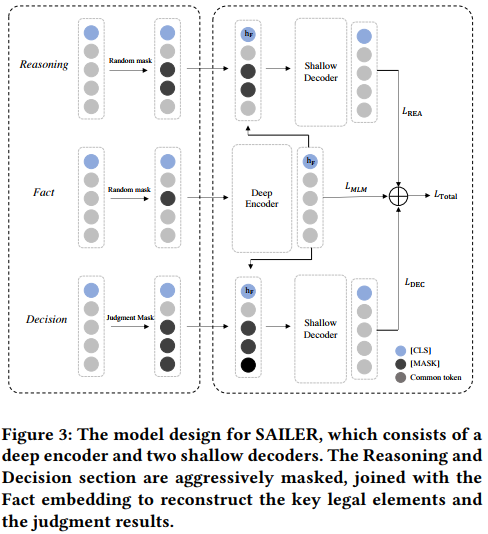
- Structure the data (Structure-Aware)
- Consists of a Fact Encoder, Reasoning Decoder, and Decision Decoder, targeting different components of legal case documents.
- The Fact Encoder uses a BERT-like model to represent the Fact section, wuhile Reasoning and Decision Decoders focuss on key legal elements and judgment prediction.
Method
- Structures the data into the following 5 sections :
- PROCEDURE
- FACT
- REASONING
- DECISION
- TAIL
- Fact Encoder: Masks tokens and uses final hidden states for representation.
- Use the final hidden state as the representation of the ENTIRE SENTENCE (hf)
- Reasoning Decoder: Reconstructs aggressively-masked Reasoning text
- Aggressively mask tokens (30~60%)
- NEEDS to rely heavily on the Fact (hf) to recover the masked information
- Enhance key element attention.
- Decision Decoder: Handles legal judgment prediction, masking according to country-specific decision formats.
- Mask information according to the country’s decision format
- IF No format -> select words with high TFIDF values to mask
Experiments & Result Analysis
Compares with existing baseline models such as Traditional Retrieval Models, Generic Pre-trained Models, and Retrieval-oriented Pre-trained Models.
SAILER dataset
- Chinese : tens of millions of case documents from China Judgment Online
- English : U.S. federal and state courts
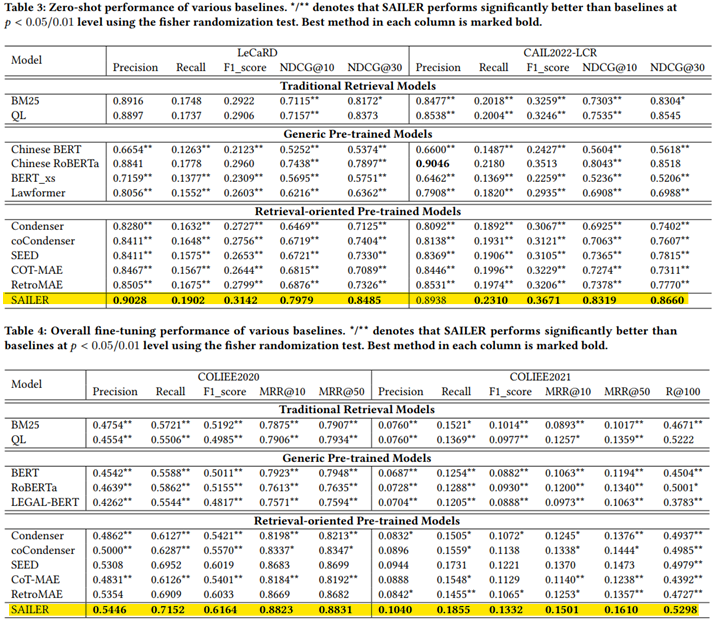
SAILER Results & Analysis
- Encoder : High masking ratio prevent generation of high-quality sentence embeddings
- Decoder : Exessive masking makes it difficult
SAILER emphasizes legal terms than SEED(retrieval-oriented model)

Contributions
- SAILER is the first model to leverage structural information in legal case pre-training.
- Proposing pre-training objectives that capture long-distance dependencies and logical knowledge.
- Extensive experiments demonstrating SAILER’s effectiveness across Chinese and English legal benchmarks.
In conclusion, “SAILER: A Structure-Aware Pre-Trained Model for Legal Case Retrieval” addresses challenges in legal case retrieval by introducing a novel framework. Through its innovative approach, SAILER significantly advances the field by emphasizing structural information and key legal elements, demonstrating its potential to enhance legal case retrieval in intelligent legal systems.