

")
This paper introduces a novel model called Hypergraph Attention Networks (HyperGAT). The purpose of HyperGAT is to enhance the process of learning text representations by offering greater expressive capabilities while simultaneously demanding fewer computational resources. The paper substantiates its claims by conducting experiments across various datasets, demonstrating that HyperGAT proves effective for tasks involving text classification.
1. Introduction
Using GNN for text classification has good performance, but it has two limitations. 1) Expressive Power. GNN focuses only on the relationship between two nodes and does not deal with multiple relationships, so it is limited in expressing the real world. 2) Computational Consumption. Due to the overload of memory usage, it uses transductive learning, which is inefficient because it needs to learn every time a document is input (transductive learning is a learning method that finds a node by leaving a node blank inside the graph).
Therefore, we need a model with high computational efficiency while increasing expressive power, and we want to solve this with the concept of hyperedge.
2. Methodology
- hyperedge
In this paper, we use the concept of hyperedge to allow multiple nodes to be included in one edge. It can be represented in two ways 1) sequential hyperedges. Divide the document into sentences and connect all the words contained in those sentences. 2) semantic hyperedges. We use LDA to topicize the document and consider the top K words as hyperedges.
- Attention Networks
When learning, there are two ways to learn, 1) node-level attention. Since not all nodes in a given hyperedge contribute equally, we use an attention mechanism to emphasize the importance of a node** (perhaps this will represent the most contributing nodes?). 2) Edge-level attention. We use it to learn hyperedges for learning nodes in the next layer (as if it represents the contribution of a hyperedge to node v?)**
3. Experiments
Meaningful results,
sequential hyperedges play a more important role than semantic ones.
*w/o attention replaced by convolution instead of dual attention
**w/o sequential, w/o semantic exclude sequential and semantic hyperedges, respectively
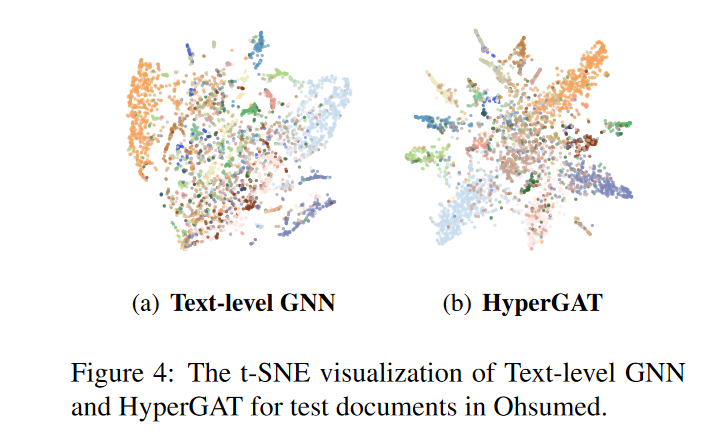
Case study
Compared to Text-level GNN, we can see that it is more expressive (23 classes)
The actual sentences are highlighted, The first three sentences represent sequential hyperedges and the last sentence represents semantic hyperedges (separated by blue). The orange color indicates nodes, with darker colors indicating higher weights.

4. Discussion
I’ll have to look at the code in the paper, but I’m trying to learn how to use sequential or semantic hyperedges for component hierarchization.